"What if a voice app of non-trivial complexity would be implemented with different approaches, and all of it would be open source? This is exactly what the ‘Dice Championship’ project is about, and I hope it provides some educational value to the voice developer community."
-- Florian Hollandt

Friday, 18:00 ET - Introduction
Florian
introduced "Dice Championship" as an open source "rosetta stone", illustrating different ways that the same non-trivial example could be written for different platforms. This project is my attempt to provide an example using very different tools than Florian uses.
Aside from the overall goal, I'm making minimal references to Florian's project. While there is likely some overlap to our approaches, I want to be as "clean room" as possible to illustrate different ways to tackle the problem.
Additionally, I'm adding in two personal goals:
- I'm going to aim to have the first implementation ready to submit for review within 48 hours. I have no clue if I can actually pull it off, but we'll see. I'm not going to code for 48 straight hours - I have other things to do, but the goal is to submit this by Sunday at 18:00 ET.
- I'm documenting every step along the way. From setting up the project and github repository, to design of the different components, to the code I'm writing, I'll be talking about everything I do pretty much as I do it.
My hope is that this provides some insight to people getting started with voice design and development about how they can do the same.
What tools?
While much of the concept and design is platform agnostic, I have to implement it in something! Here's what I'll be using, and I'll explain some of this as I go along:
- Target platform is the Google Assistant (all surfaces: speakers, mobile, displays, etc) using the Actions on Google environment
- Dialogflow for Natural Language Processing (NLP)
- Hosted using Firebase (Cloud Functions for Firebase and Firebase Hosting)
- High score table using either the Firebase RTDB or Firestore
- Coded using node.js using the multivocal library
What's next?
First up will be to setup the project, my local dev environment, and a github repository.
Feel free to ask questions and comment, and stay tuned to this page and my tweets!
Friday, 18:05 ET - Starting Setup
Actions and Dialogflow Setup
Ok, first thing, I need to setup a project at https://console.actions.google.com/
Theres my first slip-up. I chose the wrong name for the project. It doesn't change anything when it comes to the name people will use - this is strictly internal. But its irritating.
Usually I ignore this verticals page, but this time I'll select that we're building a game.
Not using any of the templates - this will be a conversational Action.
Claiming a directory entry as quickly as I can. I'll leave "Dice Championship" for Florian, and since I'll be using Multivocal, I'll claim "Multi" as part of the name.
Time to make our first Action, which is a standard invocation.
This will bring up Dialogflow, which we'll be using to setup all our phrases and Intents. Later. For now, we'll just create the project...

...and confirm things are setup.
This is all pretty basic stuff so far. Behind the scenes, it also sets up a Google Cloud project with the same project name. We'll be making use of that in a bit when we setup the Firebase project, but most of the time we can ignore it.
These pictures are also a bit of a pain for me to make, so don't expect a lot of them. {: Fortunately, we're not going to need a lot of screen shots to illustrate what is going on.
Setup Github
I'm not going to go into details about how to setup a repository, make a README, a .gitignore, and select a license, but this is under the Apache 2.0 license and the repository is open, so you're welcome to follow along.
I use a branching technique known as gitflow, even for simple projects, so if you're going to be following along, most of the work will be in the "develop" branch. We won't merge anything back into the main branch until we get our first MVP milestone and I have something for alpha testing.
You can find the develop branch at
https://github.com/afirstenberg/multi-dice-challenge/tree/develop. It looks pretty empty right now, so its time to start setting up our working environment.
Setup Firebase and Local environment
Conversational Actions rely on a webhook - running at a public HTTPS endpoint. We'll also need a place to store various other files, including our Privacy Policy, audio files, etc. Firebase has two services that make this easy for us, Cloud Functions for Firebase and Firebase Hosting. So we'll take advantage of these.
While developing, however, it can be a pain to be constantly updating the public site. Firebase lets us run a local emulation of (parts of) their environment, but we need a good way to provide that HTTPS endpoint. I like to use a tool called ngrok (https://ngrok.com/) that provides a public URL while providing a tunnel to my local machine. It also lets me look at what the HTTP traffic looks like, so if there are problems, I can examine what the Assistant sent and what I'm replying with.
Cloud Functions for Firebase supports Node 8, so I'll go with that for my language.
I've installed the firebase tool library, so all I need to do to initialize Firebase is run
firebase init
then select Functions and Hosting, choose the project that it is associated with, and confirm a few other details and it creates my initial directory structure and some files we'll need to check in.
There are three things that are new and useful to us at this point:
- The functions directory will contain our node code that runs in Cloud Functions
- The public directory contains things served through the website
- There is also a firebase.json file that defines a few configuration things for Firebase Hosting
After checking in the raw files, we need to make a few changes for our project.
I'm going to be using the multivocal library (https://multivocal.info) to help me with the code and responses. I'm a little biased on this - I wrote multivocal. But it really simplifies a lot of what needs to be done when it comes to writing Actions (and I think other voice agents, eventually), and it provides some nice features like templating, l10n, etc, etc etc. More on that later. But we need to add this to our
package.json file in the
functions directory.
npm install --save multivocal
I also like to add some configuration to the
firebase.json file that will let the hosting and the webhook function use the same hostname. This rewrites the
/assistant path for the host to use the "
assistant" function, which we'll be defining later.
"rewrites":[
{
"source": "/assistant",
"function": "assistant"
}
]
With that checked in, we're ready to begin coding, right? Well, I mean, after a snack.
Not exactly.
Friday, 19:30 ET - Conversation Design
Florian's requirements for the game are fairly simple:
In each round, the app rolls ten dice for you, adds up the face values to your score, and compares it to both your own highscore and a global leaderboard. If you improve in either of both, you get a positive message and sound, otherwise you get a soft negative response and are urged to try again.
This seems fairly straightforward, but does give us some room to examine what a conversation with this game would sound like. Let's script out a few games:
First time player
Player: Talk to multi dice championship
Google: Sure, Getting multi dice championship. <earcon>
Action: Welcome to multi dice championship. I'll roll ten dice for you, and tell you your score. Your goal is to beat your personal best and battle for the global high score. Are you ready to get rolling?
Player: Sure
Action: Ok, <dice roll sound> you've rolled three sixes, two fives, and five ones for a total of 33. A new personal high score <trumpets> and you're ranked 10th worldwide. Do you want to roll again?
Player: Ok
Action: Here we go <dice roll sound>, you got six threes, a two, and three ones totaling 23. Sorry <sad song>, you haven't improved your score. Try again?
Player: Nah.
Action: Well, hope to see you again soon as you fight for the multi dice championship!
Google: <earcon>
Returning player
Player: Talk to multi dice championship
Google: Sure, Getting multi dice championship. <earcon>
Action: Welcome back to multi dice championship. Your high score is 33, ranking you 10th worldwide. Are you ready to roll and rock?
Player: I guess
Action: ...
Ok, these look good. We cover new players (so we need to explain what is going on), returning players (so we can start with shorter text), varying some of our replies (so it doesn't get boring), adding audio, win conditions, lose conditions, and quitting. Anything else we need?
Remember, the player can take the conversation at any direction at any time. They don't necessarily want to jump into another roll or to quit.
Action: ... Are you ready to roll?
Player: What's my high score?
Action: You're currently rocking a high of 33. Shall we try for better?
We can also imagine some other questions they might ask, such as what their global ranking is.
What if they say nothing at all? Or say something that doesn't make sense?
Action: ... Shall I roll the dice?
Player: <silence>
Action: Would you like me to roll the dice?
Player: <silence>
Action: If you're still playing, I can roll the dice for you, or you can ask about your score or global ranking. What would you like to do?
Player: <silence>
Action: Perhaps we can play some more later.
Google: <earcon>
This also suggests that some of the things we need to listen for when they want to roll again are more than just "yes" or "yup" or other affirmative statements. They may also ask us to roll. Or keep playing. Or several other phrases which all mean that they're still playing.
Around now, I probably should be doing some role playing testing, to see how these sound and to see if the player can come up with other ideas that we hadn't scripted for. Either because of this, or because as we start to test we find other phrases, or things don't quite sound right, we may need to revisit some of these phrases. But this is a good start.
A good enough start that I think it's time to begin...
Friday, 20:15 ET - Building Intents in Dialogflow

I'm not going to go into detail about every Intent designed in Dialogflow. If you really want to look at
what each Intent looks like, the files will be in git and you can load it yourself.
We can start by looking at the list and how I've organized them. I tend to group them into broad categories (not always consistently) as a top level description, and then a second level (separated by a dot) describing details about what the user does. So we can see names like
event.welcome indicating this was the Welcome event, or
input.none indicating there was no input. Other names like
roll.yes indicates that they are saying they want to roll.
What isn't shown from this list is that some of these Intents may need to do the same thing. For example,
input.none and
input.unknown are similar, and we may want to handle them the same. Similarly,
ask.no and
event.quit will both lead to quitting the Action.
Remember this:
Intents represent what the user says or does, not how we handle that. How these Intents are handled in our code isn't relevant at this point.
But we do have a tool that helps us, even in this. In addition to an Intent name, which must be unique, we can also set an Action name for each Intent. These Action names can be shared between Intents, and multivocal can take action based on either the Intent name or Action name (or other criteria, but these are the most basic).
To use an example both
event.quit and
ask.no have the action name of
quit.
Some other things to note. All of the Intents are setup to use the webhook for fulfillment (we'll be configuring this in a bit) instead of using Dialogflow's static responses. Some of the Intents have training phrases, while other respond to system events (the Assistant and Dialogflow treat "quit" as something the system captures, for example, as well as detecting no input and the welcome Intent).
Dialogflow lets us export the configuration as a zip file, so I'll do so, unzip it, and check it into git.
Friday, 20:22 ET - Code!
I'm beginning to get tired, but I'd like to get some of the initial code in place. Maybe even start getting a feel for what the conversation sounds like.
There are two principles of Multivocal that are useful to understand when starting a project:
- Minimal boilerplate or code generation
- Configuration over code
As such, our boilerplate ends up looking something like this:
const Multivocal = require('multivocal');
exports.assistant = Multivocal.processFirebaseWebhook;
which just says that we're importing the Multivocal library, and that the Cloud Function named "assistant" will call the processFirebaseWebhook function that is defined by that library.
This doesn't do all that much by itself, so we need to add a place where we load the configuration. We'll put that in a separate file (although we can put it in the same file, or multiple files, it doesn't really matter), require that file, and call an init() function that we have defined there which sets up the configuration we need. So the code now looks something like this:
const Multivocal = require('multivocal');
require('./action').init();
exports.assistant = Multivocal.processFirebaseWebhook;
Setting up the configuration
In the action.js file, we start by creating an init() function that loads the configuration from a standard JavaScript object:
const conf = {
Local: {
"en": enConf,
"und": enConf
}
};
exports.init = function(){
new Multivocal.Config.Simple( conf );
};
That object is build from other objects which we'll look at in a moment. We see one attribute, "Local" which contains localized information. We have two locations to start, the "en" language and what to use if we don't otherwise define a matching language. In this case, both use the same configuration.
As we develop for other languages and locales, we'll just add the configuration for them here. Multivocal takes care of finding which one matches best.
What is in the configuration for each language? For us, the big thing is to include the responses we want. Most of our responses will be for particular action names, and we'll start out by just defining one or two simple ones. We can also define suffixes for the actions, or even just a default set of suffixes to pick from.
Defining multiple responses and suffixes is a good design practice, and helps us sound less like a robot.
I tend to break configuration down even further, which I find makes a number of things, including localization, easier. Other people may just like to put them in large configuration files. Multivocal doesn't care. (Multivocal even has ways to store this configuration in a database, but more on that another time.) This means we might define the enConf object like this:
const enConf = {
Response: {
"Action.welcome": enWelcome,
"Action.quit": enQuit,
"Action.unknown": enUnknown,
"Action.roll": enRoll,
"Intent.ask.rank": enRank,
"Intent.ask.score": enScore
},
Suffix: {
Default: enSuffixDefault
}
};
But that just means that we have to setup more objects. Before we do, a note about what we're looking at here. The entries for Response will contain the possible responses for the Action or Intent so named. (Multivocal also introduces the concept of an Outent, which is just a name you can set during processing and it will use that instead of the Intent or Action name.)
Building Responses and Suffixes
In their simplest form, these are just a list of strings which can be used to reply. Multivocal will pick one at random:
const enWelcome = [
"Welcome back to multi dice championship!",
"Good to see you again."
];
But these strings are actually templates and are fed through Handlebars (https://handlebarsjs.com) so we can include values from the Multivocal Environment or call functions that are defined in Handlebars. We'll start simple, but this is how we'll define the responses that are used after a roll for now:
const enRoll = [
"You've rolled a {{total}}.",
"Your total is {{total}}."
];
We also have some configuration for when we quit. This says that there are some base values that apply for all the following responses, and that base configuration says that we should quit as part of our response:
const enQuit = [
{
Base: {Set:true},
ShouldClose: true
},
"Hope to see you again soon as you fight for the multi dice championship!",
"Looking forward to your return to the multi dice championship!"
];
We won't fill in everything at this stage, but one thing to note is that all of these responses have been statements. They don't prompt the player if they want to do something next, which is considered a bad design practice. This is what the suffix settings are for - if the response does not end with a question mark, Multivocal will pick an appropriate response randomly and append it. You should set the responses so they make it clear that the user is being prompted to do something - usually this is best done by asking a question you expect the user to answer.
const enSuffixDefault = [
"Shall I roll the dice?",
"Would you like me to roll the dice?",
"Are you ready to roll?",
"Are you ready to roll and rock?"
];
Our code is incomplete (we don't set the Multivocal Environment setting of total anywhere, for example) but we're approaching being able to test this to see what it sounds like so far.
Friday, 23:30 ET - First Test
While I'm close to the first test, there are a few small things that need to be done.
Running local servers
I need to actually serve the code using Firebase's local emulation
firebase serve
This starts a Cloud Function emulator listening on the local port 5001, and a Firebase Hosting emulator listening on port 5000 (and forwarding requests for
assistant to port 5001). Separately, I need to create the tunnel from a public HTTPS server to the local port 5000 using
ngrok
ngrok http 5000
As part of this,
ngrok will tell me what the public HTTPS URL is. I'll need this when configuring Dialogflow to tell it where the fulfillment webhook is.
Configuring Dialogflow
With this URL, we need to set it in Dialogflow's "fulfillment" section.
Test!
Ok, the moment of truth. We can go to Dialogflow's "Integrations" section and start the test for Actions on Google. It will bring up the AoG simulator, already suggesting we can talk to multi dice championship.
Ask it to talk to multi dice championship and we get...
... an error. Which doesn't, on the surface, make sense. I'll poke at it a little tonight, but further work might have to wait till morning.
 Well... that's odd
Well... that's odd
The test isn't working in the simulator, but if I try to test it out on a real Assistant, it seems to work ok. That is, at least, somewhat reassuring. Or not, since usually if it works in one place, it works everywhere your account is setup.
At any rate, we see that it is using our responses. If we play with it a few times, we'll see that it picks random responses and suffixes. We see that it doesn't have the result of a roll, so it leaves this blank.
I did notice one bug, however. I defined the Action name for
input.none and
input.unknown to be "input.unknown", but the code just refers to it as "unknown". Once I change the definition of these two Intents, it seems to be working fine.
I'm still having trouble with the simulator, so I think its time for a nap.
 And then...
And then...
... just like that... for no obvious reason, the simulator is working.
I hate heisenbugs.
But with that, it definitely is time for a nap.
What's next?
Now that we can test things, we can make some serious progress on the code. Responses are good, but we need to compute some values for the roll and then save them to report as a high score. We also want our responses to include some audio, and not just rendered text to speech. We can tackle these pretty easily. I think.
Beyond that, we then need to work on the high score table, which is probably the most complicated part of the entire project. If we get that done quickly enough (and I hope I do), I'd like to implement a new feature introduced for games on the Assistant - the Interactive canvas.
But all that is for tomorrow.
Saturday, 06:30 ET - Game logic
Time to begin implementing the game logic, starting with rolling the dice.
With Multivocal, there are a few places to put this kind of logic, depending on when it should be executed. The two most common are
- Builders which are executed for every request from the user. These are typically used to setup values needed every (or almost every) time.
- Handlers which are setup against specific Intents or Actions to compute values necessary just for that Intent/Action and determine the responses.
We'll need both, but right now, we just need to build a handler for the "roll" action. Both kinds, however, have a pattern that is common in Multivocal
- They take a single parameter that contains the Multivocal Environment
- They return a Promise that will resolve into the Multivocal Environment, possibly updated.
Just what is the Multivocal Environment? Nothing complicated - just an object with attributes. Multivocal builds some of these attributes for you (for example, Body contains an object with the body of the request converted from JSON), and you're free to set attributes yourself. Attribute names that start with capital letters (and some other things) are reserved by Multivocal. The Environment is passed to the template engine when we build responses, so we have access to any values we or Multivocal have set.
Why return a Promise, even for functions that aren't asynchronous? Because they may be at some point in the future, and we wanted to keep the function interfaces as consistent as possible. We also found the consistently less confusing for developers - return a Promise. Easy.
 The roll handler
The roll handler
This actually leads to a dilemma for me. Rolling dice are straightforward, but would this be a good place to illustrate how to do an API call? There are, after all, APIs that let me specify how many dice to roll and get back a JSON result. I decided not to - easy enough to add later, and we'll have other examples of how to do API calls later.
I won't show all the code (go check out the repository), but our roll handler needs to start out by rolling the dice, getting the total, and storing these values in the Environment. It then needs to call the default handler, which is responsible for updating some internal counters and selecting which response to make, and return the Environment which it returns.
function handleRoll( env ){
// Roll the dice
let dice = roll( 10, 6 );
env.dice = dice;
// Add them up to get the total
let total = dice.reduce( (total, val) => total + val );
env.total = total;
// TODO: Check if this is a new high score
return Multivocal.handleDefault( env );
}
We register this handler in our init() function, which now looks like this
exports.init = function(){
Multivocal.addHandler( 'Action.roll', handleRoll );
new Multivocal.Config.Simple( conf );
}
A quick test with the simulator (which seems to be working this morning) indicates it now reports our score.
High score
This is a good start for the morning, but we also need to store the high score for this user. Actions on Google, and Multivocal, provide a way to store a few K of data for each user in between sessions. Like web cookies, users can both see and clear this data, so you don't want to store a lot, or store secrets, but this is a reasonable place for us to store the high score.
Multivocal provides access to this state in an Environment path called User/State. This is the same as writing env.User.State in JavaScript, but it has undefined value safety. I move between the Multivocal utilities that let us address things with a path and the JavaScript native way to access things depending on what is most useful at the time.
Since most of our Intents end up using the high score, this is a good place to use a Builder. This will be a straightforward builder - get the value from a path in the Environment and save it to a different one. If it doesn't already exist - just set it to 0.
function buildHighScore( env ){
env.highScore = Util.objPathsDefault( env, 'User/State/highScore', 0 );
return Promise.resolve( env );
}
We register this builder in our init() function again, so it now looks like this
exports.init = function(){
Multivocal.addBuilder( buildHighScore );
Multivocal.addHandler( 'Action.roll', handleRoll );
new Multivocal.Config.Simple( conf );
}
We'll make a change to the roll handler so it calls a new function that will check if the total is greater than the existing high score and, if so, set a new high score in the Environment. It also sets a flag in the Environment to know if we have a new high score or not, which we'll take advantage of later.
Heres the new function
function conditionallySetHighScore( env ){
if( env.total > env.highScore ){
env.isNewHighScore = true;
env.highScore = env.total;
Util.setObjPath( env, 'User/State/highScore', env.highScore );
} else {
env.isNewHighScore = false;
}
return Promise.resolve( env );
}
and our change to the roll handler
// Check if this is a new high score
return conditionallySetHighScore( env )
// Produce responses, etc.
.then( env => Multivocal.handleDefault( env ) );
For now, we'll also make a change to the responses for the ask.score Intent, to make sure it works.
const enScore = [
"Your high score is {{highScore}}.",
"So far, {{highScore}} is your best."
];
We don't need to change the handler for this (we didn't write one) - it just uses the Default handler which picks one of the responses, and we've already populated the highScore in the Environment as part of the builder.
A quick test shows that things work well.
Not bad for a half hour of work (which is mostly spent typing up this explanation).
Saturday, 09:30 ET - Better Responses
Our design has some elaborate sets of responses, including different welcome messages if this is the first time or a repeat and a summary of the dice rolled. Even Florian noticed this and commented on it
in a tweet.
Our responses have proven things work. Now its time to make them more conversational.
A more welcoming welcome
We want different messages the first time someone visits, a little different for the next few, and then something different after that. Multivocal determines our level by going through a list of criteria, and the first criteria that matches gets its level assigned. If nothing matches, it is given level 0 or a default. This level is then appended to the name we use when looking at responses. We don't have to have responses for each level - if there isn't, it uses the default responses.
In our configuration for the
welcome Action, we define two levels, if this is their first visit we use level 1, otherwise if they've been here fewer than 5 times, it will be level 2. Multivocal keeps track of the total number of visits for us - we don't need to do anything else on that front. These levels are stored as part of our configuration
Level: {
"Action.welcome": [
"{{eq User.State.NumVisits 1}}",
"{{lt User.State.NumVisits 5}}"
]
}
We'll add a few new entries for the locale specific responses. We don't need to add it for both levels, but we choose to do so
"Action.welcome.1": enWelcome1,
"Action.welcome.2": enWelcome2,
"Action.welcome": enWelcome,
And finally we'll add the new responses, and adjust the default ones a bit.
const enWelcome1 = [
"Welcome to multi dice championship. "+
"I'll roll ten dice for you, and tell you your score. "+
"Your goal is to beat your personal best and battle for the global high score. "+
"Are you ready to get rolling?"
];
const enWelcome2 = [
"Welcome back to multi dice championship! "+
"This is your {{ordinalize User.State.NumVisits}} visit "+
"and your score so far is {{highScore}}.",
"Here on your {{ordinalize User.State.NumVisits}} visit to "+
"multi dice championship your score so far is {{highScore}}."
];
const enWelcome = [
"Good to see you again. Your high score is {{highScore}}.",
"Welcome back! So far, your high score is {{highScore}}."
];
As an aside, this took me a while to do because I went chasing a red herring. Normally, Multivocal should have provided those levels in its default configuration. But I forgot that it defines it for an action named multivocal.welcome and not welcome. I could have adjusted the action name, but decided to leave it this way to explain what was going on better.
Roll results response
As a first step towards the roll results we want, we can made a simple change to show all the dice in
our response.
const enRoll = [
"You've rolled {{Oxford dice}}, totalling {{total}}.",
"Your total is {{total}} from rolling {{Oxford dice}}."
];
This works ok. But we also wanted to tell the user if they have a new high score or not, so we'll need to add some conditionals to our templates.
const enRoll = [
"You've rolled {{Oxford dice}}, "+
"{{#if isNewHighScore}}for a new high score of {{highScore}}!"+
"{{else}}totalling {{total}}, which doesn't beat your high of {{highScore}}."+
"{{/if}}",
"Your total is {{total}} from rolling {{Oxford dice}}, "+
"{{#if isNewHighScore}}which is a new high score!"+
"{{else}}but this doesn't beat your high score of {{highScore}}."+
"{{/if}}"
];
Including conditionals in our template is good, but we don't want to push them too far. Like with most templating languages, we need to be careful to not put too much logic into our templates, but just enough that it improves our responses without making them too complex.
Looking closer to what we want, but we really wanted some audio to go with it. And while we're at it, listening to those numbers rattled off really gets... um... annoying.
Text and SSML
Let's tackle that list of numbers first. We certainly don't want to hear that every time, but it might be useful if we're using the Assistant on a screen to be able to see it. So we'll continue to use the same text when displaying the results, but we'll
say something shorter.
This takes us into how Multivocal handles Responses. Most of the response entries have been strings; when Multivocal gets a response that is a string, it converts it into an object with the
Template/Text attribute set to the string, and then has the template engine process all the attributes set on the
Template attribute (which should be an object). The results of the processing are copied into the
Msg attribute in the Environment. If we provide an object with a
Template attribute, the same thing happens, but it expects the
Text and/or
Ssml attributes to be set.
const enRoll = [
{
Template: {
Text: "You've rolled {{Oxford dice}}, "+
"{{#if isNewHighScore}}for a new high score of {{highScore}}!"+
"{{else}}totalling {{total}}, which doesn't beat your high of {{highScore}}."+
"{{/if}}",
Ssml: "You "+
"{{#if isNewHighScore}}have a new high score of {{highScore}}!"+
"{{else}}rolled {{total}}, which doesn't beat your high of {{highScore}}."+
"{{/if}}"
}
},
{
Template: {
Text: "Your total is {{total}} from rolling {{Oxford dice}}, "+
"{{#if isNewHighScore}}which is a new high score!"+
"{{else}}but this doesn't beat your high score of {{highScore}}."+
"{{/if}}",
Ssml: "Your total is {{total}}, "+
"{{#if isNewHighScore}}which is a new high score!"+
"{{else}}but this doesn't beat your high score of {{highScore}}."+
"{{/if}}"
}
}
];
When we do this, we get the text version, including the list of numbers, and a spoken version which is shorter. How about some of those audio effects? Sure, we can use the SSML <audio> tag to add them.
const enRoll = [
{
Template: {
Text: "You've rolled {{Oxford dice}}, "+
"{{#if isNewHighScore}}for a new high score of {{highScore}}!"+
"{{else}}totalling {{total}}, which doesn't beat your high of {{highScore}}."+
"{{/if}}",
Ssml: "<audio src='https://{{host}}/audio/allen-roll.mp3'></audio>"+
"You "+
"{{#if isNewHighScore}}have a new high score of {{highScore}}!"+
"<audio src='https://{{host}}/audio/allen-yay.mp3'></audio>"+
"{{else}}rolled {{total}}, which doesn't beat your high of {{highScore}}."+
"<audio src='https://{{host}}/audio/allen-boo.mp3'></audio>"+
"{{/if}}"
}
},
{
Template: {
Text: "Your total is {{total}} from rolling {{Oxford dice}}, "+
"{{#if isNewHighScore}}which is a new high score!"+
"{{else}}but this doesn't beat your high score of {{highScore}}."+
"{{/if}}",
Ssml: "<audio src='https://{{host}}/audio/allen-roll.mp3'></audio>"+
"Your total is {{total}}, "+
"{{#if isNewHighScore}}which is a new high score!"+
"<audio src='https://{{host}}/audio/allen-yay.mp3'></audio>"+
"{{else}}but this doesn't beat your high score of {{highScore}}."+
"<audio src='https://{{host}}/audio/allen-boo.mp3'></audio>"+
"{{/if}}"
}
}
];
There are a few issues here.
The first is that the Actions on Google audio library is... weak. Although their games and actions have some nice audio for rolling dice and cheers and such, these aren't available to outside developers. So I had to make my own. At some point, I'll replace these.
The second is that the audio tags make the templates look messy. And there is a bit of redundancy. Could I just put those in the configuration somewhere? I probably should, but I wanted to have the reference to host be dynamic so I wouldn't need to change anything when I moved from my local development to production.
The third is that property host. Multivocal doesn't (yet) provide that information, so I wrote a builder that uses a template to get the information from other properties we're provided.
These last two points are certainly things that Multivocal should provide, and I'll probably add them sometime. But not this weekend.
What's next?
I've made a lot of progress so far today! We're not even half-way through my 48 hours, and I've implemented almost all of the features.
I wanted to do more tweaking of the responses, but I think these are good enough for now. I think there also needs to be a way to ask for what die were rolled the last time, in case we don't have a screen and want to know what the roll was. I also want a way I can reset my high score.
These aren't hard, but I'll probably work on them later. I have something I want to do at 14:00 ET, and this break gives me the opportunity to think about how to tackle the last big requirement we have - the leader board.
Saturday, 13:45 ET - Leader Board Design
I've been pondering this problem all afternoon. (Ok, and also taking some time to relax and think.)
Overthinking score distribution
The issue is that the leaderboard for this game is a
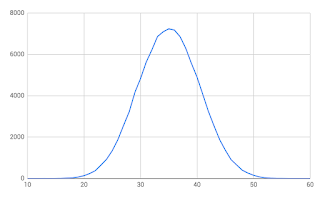
very unusual type of board. There are a fixed number of possible scores (51, ranging from 10 to 60 inclusive), and it is very likely that there will be clustering. Although the more I thought about it, not clustering in the way I first figured.
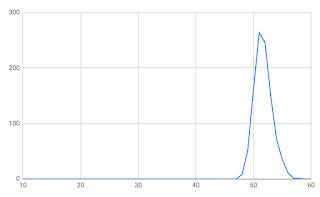
When I first thought about it, I assumed that the clustering would look like a bell curve. Anyone who has done basic statistics would assume this. When I ran 100000 rolls of 10 dice and plotted the results, this is exactly what I got (see the chart).
But this is
not the chart of a high-score table. This is the chart of a
score table. If 1000 people each played 100 times, this is how their scores would be distributed.
To get a high score distribution, I simulated 1000 people each playing 1000 times and recording what the highest score was for
each person. This yielded a very different table (see the other chart). The lowest score on this table is 48. I'm sure there is some statistician out there who can give a formula for this curve, and that it might even have a name... but I'm not that person.
What it does tell me is that, over time, scores will cluster towards the top and then taper down slowly. Players starting out are more likely to be towards the tail, but as they play more, they'll find themselves stuck towards the top.
This has serious implications for a leaderboard, where 11 people with a score of 56 will be tied for 3rd place, meaning the 35 people with a score of 55 will be tied for 14th place... and so on down the line. It also means we can't assume the person in 1st place has a perfect score.
So what does this mean...
This makes the leaderboard relatively simple. 51 counters are fairly small and easily saved in (and fetched from) a database as long as there is an atomic way to increment or decrement those counters. To compute the rank of a particular person given their individual high score, all we need to do is go through the counters strictly greater than their score, total them up, and add 1. That is a pretty simple loop. If we needed (or wanted) to also store the users who have that score, we can do so, but it wouldn't need to be involved in the count.
All of that is (relatively) easy to implement using Firestore, so I'll start that coding now.
Saturday, 20:00 ET - Leaderboard Coding
Firestore is a no-SQL database that imposes a number of restrictions on how data is stored. These restrictions ensure that database operations work as efficiently as possible. Fortunately - these restrictions fit into our needs exactly.
Database structure
Firestore starts as a
named collection of
documents. Each document has a unique id for that collection, and can be treated as a JSON file (with some additional features). Some of the attributes in the document can be used for indexing and ordering. Queries are based on ordering against one of the fields, setting the boundaries for what is returned, and going through the resulting documents.
Given this, our structure is
- A collection named "leaderboard". (We can have other collections that contain configuration, for example.)
- In this collection, there are 51 documents named "10" through "60". These document IDs are just to make it easy for us to look at in the data browser. We can't use them for ordering.
- Each document contains just two fields
- The score. This is a number that matches the document ID.
- The number of people who have this as their high score.
Code basics
I put most of the logic to handle leaderboards into its own file, to manage things a little better, although some of the functions need to be accessed from our existing code.
Similar to our previous module, there is an
init() function which needs to be called from index.js. One of the things it does is initialize the database to be used as configuration. This lets us change any of our other configuration by editing the database, without having to re-deploy code.
Getting our place in the world
Each time an Intent is called, we'll get our place on the leaderboard. As before, we do this by registering a builder in
init(). It will call this function
function buildLeaderboard( env ){
let highScore = env.highScore;
// If the user doesn't have a high score, we can't set the rank
if( highScore ){
return leaderboardFromScore( env, highScore );
}
return Promise.resolve( env );
}
This only tries to get our position in the leaderboard if we have a high score set. If so, it calls an function that gets the information and saves it into the Environment
function leaderboardFromScore( env, highScore ){
return rankInfo( highScore )
.then( info => {
env.leaderboard = info;
return Promise.resolve( env );
});
}
The rankInfo() function is what really does the work. It requests documents with a score from 60 to our score, inclusive. It then goes through these documents. If the score isn't our current score, we add the number of players with that score to the total rank. If it is the same as our score, we figure out how many other people we share our glory with. We'll return a Promise that resolves to an object with this data.
function rankInfo( score ){
const leaderboard = db.collection( path );
return leaderboard.orderBy('score','desc').endAt( score ).get()
.then( snapshot => {
let ret = {
rank: 1,
peer: 0
};
snapshot.forEach( doc => {
let data = doc.data();
let docScore = data.score;
let docCount = data.count;
if( docScore === score ){
ret.peer = docCount - 1;
} else {
ret.rank += docCount;
}
});
return Promise.resolve( ret );
})
}
This can all be done quickly, no matter how many people have played the game.
Movin' on up
What happens when we get a new high score? We need to
- Remove ourselves from our existing high score in the leaderboard
- Add ourselves to the new high score
- Get our new rank and peers, as above
We'll do this as a batch operation, making sure we can do the first two things atomically. After that, we'll call leaderboardFromScore() to update our Environment.
function changeHighScore( env, scoreDec, scoreInc ){
let batch = db.batch();
if( scoreDec ){
const pathDec = `${path}/${scoreDec}`;
const refDec = db.doc(pathDec);
batch.update( refDec, {count:Firestore.FieldValue.increment(-1)} );
}
if( scoreInc ){
const pathInc = `${path}/${scoreInc}`;
const refInc = db.doc(pathInc);
batch.update( refInc, {count:Firestore.FieldValue.increment(1)} );
}
return batch.commit()
.then( () => {
return leaderboardFromScore( env, scoreInc );
})
}
exports.changeHighScore = changeHighScore;
This is exported because we may need to call it from conditionallySetHighScore() which is part of our roll handler.
Updating responses
We can include this leaderboard information in any of the responses we want, but I'm going to just update the response to "What is my rank?" for now.
const enRank = [
{
Base: {Set:true},
Criteria: "{{gt leaderboard.peer 0}}"
},
"You're tied for {{ordinalize leaderboard.rank}} place "+
"with {{leaderboard.peer}} other {{inflect leaderboard.peer 'player' 'players'}}.",
{
Base: {Set:true},
Criteria: "{{eq leaderboard.peer 0}}"
},
"You're in {{ordinalize leaderboard.rank}} place."
];
There are two important bits here.
The first is that we have different responses if we're tied with other players, or if we're the only one at this level. We could have used the templating methods from before, but the phrases are so different that using template conditionals would make for a very messy string.
Instead, we set a Base response, which contains parameters which should be applied for future responses, but not be used itself. (That's what the Base: {Set:true} part means.) In this case, we set a special parameter that says the Criteria specified should be evaluated and, if true, then the response should be considered to be returned. If not, it isn't included in the possible list of responses.
The second bit is that we will say either "with 1 other player" or "with 2 other players", properly pluralizing the word. Visually, we could get away with "player(s)", but we can't do that when speaking, so we might as well do the right thing. This is one of the advantages of using templates this way.
Other code
There are a few other code additions. There is a function that created the 51 slots we needed in Firestore, since doing that by hand was annoying. I've also added the code to reset our account. There are some bits of interest in it, but I may discuss them tomorrow. I'm getting tired.
Sunday, 00:30 ET - Status?
It took me a bit to design and properly write the Firestore code, and even as it stands, it could probably do with some better error handling.
There are still some changes I want to make in the responses, such as adding your rank when you first start the game, reporting the last roll you did, and some other tweaks.
I have just under 18 hours till my self-imposed deadline to submit - and we essentially have met our MVP target. I need to allow some time to write the Privacy Policy and Terms of Service, but tomorrow morning I think I'll add some multi-modal features.
Sunday, 07:00 ET - Screen a la Mode
Well, I slept in more than I wanted, and I'm down to 11 hours till I want to submit. (I may let that slip a little... but just a little. And I can also make some tweaks afterwards. But the main functionality has to be ready.)
This morning I'll be adding support for one of the newest (and possibly coolest) features of AoG - the Interactive Canvas. This will let us do a full screen display on a Smart Display or Android device.
The best part? This is just HTML! And Multivocal makes this disturbingly easy.
The hardest part of this for me is that my page design tends to look like it is stuck in the late 1990's.
Canvasing the browser
The Interactive Canvas provides a pretty complete HTML page, including standard CSS and modern JS that we'd find in Chrome. It is missing a few things (such as pop-ups and local storage), but you shouldn't need these in a voice-first Assistant environment anyway.
So our first step will be to create an HTML page and some JS.
The header of the HTML needs to load the library for the interactiveCanvas object, which gives us some functions and events to take advantage of the Assistant.
<script src="https://www.gstatic.com/assistant/interactivecanvas/api/interactive_canvas.min.js"></script>
In our body, we'll make a simple structure, and take a first stab at what we think we'll need for content.
<div id="header"></div>
<div id="body">
<div id="msg"></div>
<div id="dice">
<img id="die0" class="die">
<img id="die1" class="die">
<img id="die2" class="die">
<img id="die3" class="die">
<img id="die4" class="die">
<img id="die5" class="die">
<img id="die6" class="die">
<img id="die7" class="die">
<img id="die8" class="die">
<img id="die9" class="die">
</div>
</div>
The header is some space we need to allocate for the Assistant's use - we'll get the size of it from the library shortly. The rest of the body contains space for our message and then dice which we'll animate with images. Note that, despite the name, we don't use the <canvas> tag anywhere. We could do so, if we wanted, but I'm going with images this time.
At the bottom, we'll load our own JavaScript.
<script src="js/assistant.js"></script>
A really really simple HTML page (I told you my page design is from the 1990's), but you're free to use whatever libraries, frameworks, and toolkits you want. (Anyone want to volunteer to improve this page?)
In our JavaScript, when its initialized, we'll get the height of the header using interactiveCanvas.getHeaderHeightPx() and set our header element to reserve the space.
interactiveCanvas.getHeaderHeightPx().then( height => {
let header = document.getElementById('header');
console.log('height',height,window.innerHeight);
header.style.height = `${height}px`;
});
We then setup callbacks for two events that the Assistant will send
- onUpdate - is generated when our Action says something and sends data to the canvas at the same time.
- onTtsMark - is triggered at certain points during the audio.
- Right now, we're guaranteed marks when the audio begins and ends.
- We can also use SSML to set marks during the message, but support for these is expected in an upcoming release.
- (We can, for example, set a mark after the dice rolling audio, start the dice rolling at the beginning of the message, and stop them rolling after that audio.)
interactiveCanvas.ready({
onUpdate: data => onUpdate( data ),
onTtsMark: mark => onTtsMark( mark )
});
Of the two functions, our onUpdate() function is the only one doing work right now. When the Action sends a response, we want it to display the text message in the "msg" area. It will get that message from the data Multivocal sends.
function onUpdate( data ){
console.log('update',data);
let msg = document.getElementById('msg');
msg.innerText = data.Send.Text;
}
Wait. How does Multivocal know to send this data?
Paging Multivocal. Multivocal to the white phone.
Multivocal needs to be configured with the URL of the HTML page to load. We'll do this with a new entry to the Settings in our configuration.
Page: {
Url: "https://{{host}}/assistant.html?session={{Session.StartTime}}"
}
That's it.
Honest, that's it. Multivocal takes care of the rest. The "session" parameter in the URL is to make sure we break the cache during testing.
How does Multivocal know to send the text? By default, it is configured to send the name of the Intent and Action, the Text and Ssml being sent, along with some other information.
 Other miscellany
Other miscellany
The only other thing we need right now is to enable the Interactive Canvas in the Action Console. This is done under the "Deploy" tab, way down at the bottom of the page.
With this change, we can test it on the simulator to see how it works. Using the simulator here helps a lot - we have access to our browser's console and to the DOM inspector.
A quick test shows its working fine, although it doesn't add much (anything) from what we had before. Making it more interesting will be our next task.
Sunday, 09:30 ET - Crafting the Canvas
To do something more interesting, however, we need to send the data that we have in the server as part of the Action down to the display so it can format the data how it wants to. If you think of this for a few moments, you realize that this is the same as what Multivocal itself does - get data and format it so it can be spoken.
So at first blush, we can specify what is sent to the client as part of our template. And Multivocal does allow this.
But since we probably want most data we generate to be sent to the canvas, or at least a clearly defined subset, Multivocal lets us set this in our Settings. So we'll specify what values from the Environment we want sent as part of the Page configuration.
IncludeEnvironment: [
"IntentName",
"ActionName",
"dice",
"total",
"highScore",
"isNewHighScore",
"leaderboard"
]
Multivocal takes care of the rest, and the data parameter delivered to our onUpdate() contains those values that have been set. So "total" won't be set on our welcome Intent, but the high score and leaderboard information will. (We also get the Action and Intent name, so we can display different things for different phases of the game, but I'm not using that yet.)
With this new data, we change onUpdate() to use some of it.
function onUpdate( data ){
console.log('update',data);
const scoreValue = document.getElementById('score-value');
const highScoreValue = document.getElementById('high-score-value');
const highScoreNew = document.getElementById('high-score-new');
scoreValue.innerText = data.total || '';
highScoreValue.innerText = data.highScore || '';
let highScoreBadgeClass = data.isNewHighScore ? 'visible' : 'hidden';
highScoreNew.className = highScoreBadgeClass;
}
These make use of new layouts for the msg area which we have in the HTML
<div id="msg">
<div id="score">Score: <span id="score-value"></span></div>
<div id="high-score">
High Score: <span id="high-score-value"></span>
<span id="high-score-new" class="hidden">NEW!</span>
</div>
</div>
This feels better. But is still pretty boring. But I think we have most of the information we need to make it look better.
Sunday, 12:00 ET - Getting Graphical
I hesitate to say too much here, since people will mock my page layout skills, but a few things to mention are in order.
We need to create a layout that works equally well for both portrait layouts, which we may find on a phone, and landscape, which are more likely on a Smart Display.
I'm going to handle that, at least for now, by having the dice layout in a mostly portrait format, but pushing it to the right of the screen when we're in landscape mode. I'll also change the font size of the text in these cases, since we have lots of space we can use.
#msg {
font-size: 21pt;
}
.die {
width: 30%
}
.die.spaced {
padding-left: 15%;
}
@media (orientation: landscape) {
#msg {
font-size: 34pt;
float: left;
width: 60%;
}
#dice {
float: right;
width: 40%;
}
}
Actually displaying the dice wasn't difficult - we're already sending the data down, we just need to set the src of the <img> tag once we know which one we should show.
if( data.dice ){
for( let co=0; co<data.dice.length; co++ ){
document.getElementById(`die${co}`).src = `img/dice-${data.dice[co]}.png`;
}
}
I really want to have some nice rolling effects, so it reveals the dice one at a time during the rolling audio. That isn't too difficult, but I also want to add some other audio commands... and a better graphic if you have a new high score... do more with the global ranking (both in audio and visually)... make sure layouts work correctly... add a "roll" button or some other control on screens...
But I think we've hit all the major features that I wanted when I thought about what I wanted to do, and some of those changes we can fiddle with and add later. Now its time to start getting ready to release.
Sunday, 14:00 ET - Prepare to Launch
Time for a checklist of what I need to do to prepare for launch. At least a Beta launch:
- Privacy Policy and Terms of Service documents
- Small and Large icons for the directory listing
- Deploy everything to Firebase and change the Dialogflow URL

The important part about the Privacy Policy and TOS are that they make clear what we do with the information that we get about users (forget most of it as quickly as possible) and what they can expect from us in general (very little). Since things may change in the future, it is important that they learn how to find out about those changes as well.
I'm no graphic designer, so I'm going to use a dice theme for the logo, which I think is at least clever, if not terribly pretty.
I'm going to hold off on the deployment just a wee bit longer. See if there isn't another feature I can't slip in first. Once we release, any changes to the Intent phrases or any other console configuration can cause issues. We can change the responses all we want - but the trigger phrases are locked in until we do another release (which may require another review).
Sunday, 16:00 ET - Anything else to say?
Well... yes. There are probably a few other Intents that we should have in place:
- "about" or "version" or something along those lines
- "help"
- "what did I roll" or "repeat" (these might be different in other cases, but I think they work well as the same Intent in our case)
These are pretty straightforward - none of them require new handlers, but mostly changes to the responses (which I may edit further later). There are two bits of small code changes that are added.
The first is that, when we roll the dice, we need to save the dice roll array and the total in Session state. Multivocal and Dialogflow maintain this information for us for the duration of the conversation (unless we clear it). It involves adding two lines to rollHandler() in relevant locations:
Util.setObjPath( env, 'Session/State/dice', dice );
Util.setObjPath( env, 'Session/State/total', total );
We use these Environment paths in the response.
The second is that we need a name and version from somewhere. Since we have a
package.json file that contains this info, its a logical place to put it (since I'm pretty good about updating it when I do a release), so we need to include it into our Environment Setting.
Setting: {
...
Package: require('./package.json'),
...
}
I might tweak some of the responses later, but at least we have something in place, and the Intents are built.
Sunday, 17:00 ET - Release the hounds!
Installing things in Firebase is pretty straightforward:
- Check everything into git, and start a new release branch
- Update the package.json with the latest version. I match the major version to Google's notion of what a "release" is (ie - something that has to go before review).
- Use firebase deploy to upload everything to the Cloud Functions and Firebase Hosting.
- Change the URL used for fulfillment in Dialogflow to the production URL that Firebase Hosting makes available to me.
And then test.
Sunday, 17:25 ET - Test and Review
My testing continues to go well, but now its time to open it up to others as well.
The moment of truth.
I'll add a few Alpha testers, who need to provide me their accounts so I can permit them, and who will have access before review completes.
Once I do that, I'll submit the Action for Beta Review. This allows up to 200 testers to have early access, but Google will review the Action before it enters Beta.
However, once they approve it in Beta - I can release it to production at any time.
Sunday, 18:00 ET - 48 hours later, and what's next?
Well! That was quite a ride for me! I got most everything accomplished that I wanted, and was able to sleep and do some other activities this weekend as well.
There
are some more things I want to do with the game, and I would love it if others stepped up and shared their knowledge about doing so, including:
- Translating it to other languages and locales. Dialogflow and Multivocal make this fairly easy (the language portions are isolated, so fairly easy to translate, and the two packages take care of most of the rest of the work), but I'm rather poor at other languages, so I'd love to work with soemeones to do this translation.
- A better visual layout and a few screen features. I think its ok, but there are better things that could be done to make it truly wow. (And its just HTML! Lots of people are good at this!)
- Multivocal lets us add analytics fairly easily, and I should have put more of that in place.
- Some better audio responses.
- Some improvements to Multivocal (around the hostname and some other default configurations).
But all of that will wait for another day.
Speaking of waiting, the biggest wait will be till Google approves the Action. They say 2-3 business days, but that Actions that use the Interactive Canvas can take a little longer since it was just released. And that assumes they don't find a problem.
But this concludes this blog entry. Further updates will be on twitter, of course, and maybe I'll post more to this blog now that it is alive again. Expect a good mix of design, philosophy, history, and code. Florian and I will probably co-write a blog entry of some sort, discussing how our approaches differed. I appreciate everyones support for the past 48 hours, but special thanks to Florian for cheering me on every step of the way.
BCNU


 This notion of "how we do it now in the physical world" continues when we look at voice and tools we use in business. When I tell people about Vodo Drive, and how it lets you work with a spreadsheet with your voice, I typically get a funny look. "That doesn't seem very easy to use," is a typical response, "Isn't it odd and difficult to say things like 'go up' and 'go to cell C3'?"
This notion of "how we do it now in the physical world" continues when we look at voice and tools we use in business. When I tell people about Vodo Drive, and how it lets you work with a spreadsheet with your voice, I typically get a funny look. "That doesn't seem very easy to use," is a typical response, "Isn't it odd and difficult to say things like 'go up' and 'go to cell C3'?"
 One common way to do so is to start with a big task, and to break it into logical, smaller, parts. Let's look at a very simple example
One common way to do so is to start with a big task, and to break it into logical, smaller, parts. Let's look at a very simple example
































